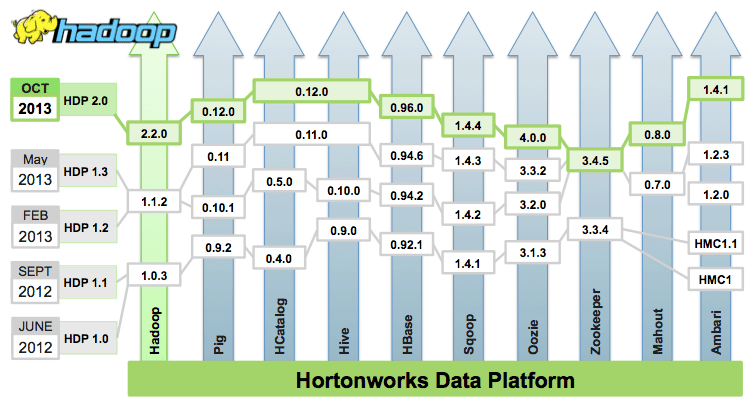
This news might not be new but something i would like to put inside my blog as to do list. Sparks is enabled by Hortonworks as announced last month June. Cloudera has similar release in February this year. Seems like Sparks is getting a traction.
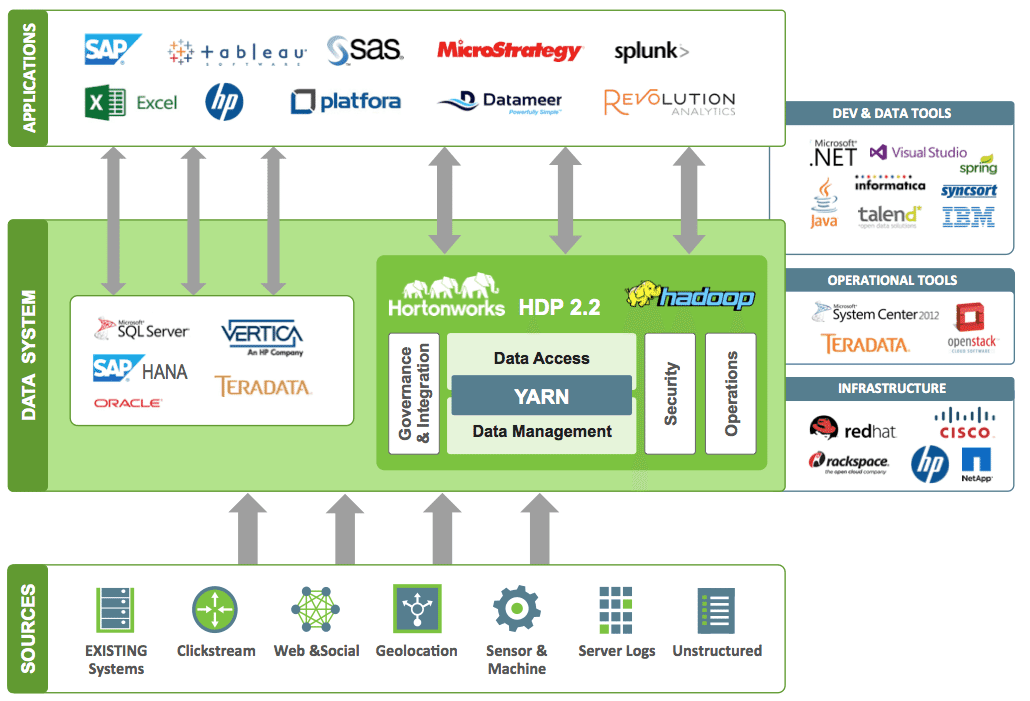
Below is the high level architecture of Sparks and other members in hadoop big data stack.